Esta será una serie de publicaciones de blog para cubrir cómo funcionará Access con las tablas vinculadas de ODBC. Vamos a ver qué hace Access en segundo plano mientras trabajamos con tablas vinculadas ODBC. La información está destinada a ayudarnos a comprender cómo Access transformará las consultas que hacemos sobre una tabla vinculada y qué podría suceder para que podamos ser más efectivos en la solución de problemas de rendimiento. Aunque usamos SQL Server como back-end, el contenido es aplicable para diferentes backends que usan ODBC.
Tabla de contenido:
Habilitar el seguimiento de ODBC SQL
Efecto de los tipos de Recordset en una consulta SELECT
Insertar un registro en un conjunto de registros
Actualización de un registro en un conjunto de registros
Eliminar un registro en un conjunto de registros
Filtrando el conjunto de registros
Ordenar el conjunto de registros
Efecto de joins en un conjunto de registros
Joins heterogéneas
Efecto de incluir un campo Rowversion
Índice único del lado de access

La serie se centrará solo en el contexto de Access / DAO. Las cosas pueden ser diferentes cuando usamos ADO en VBA, pero eso no está en el alcance por ahora, porque cuando usamos DAO, Access hará varias cosas para satisfacer nuestras solicitudes, de otro modo serían imposibles. Un buen ejemplo es una consulta de Access que hace referencia a una función VBA. No puede ejecutar la función VBA en SQL Server, pero Access no se queja. Entonces, ¿qué pasa realmente?
Lo primero que debe hacer para poder mirar detrás de las cortinas es habilitar el rastreo ODBC SQL. Aunque podemos usar SQL Server Profiler, es muy útil observar cómo Access formatea el ODBC SQL. Funcionará con cualquier fuente de datos ODBC y no solo con SQL Server. Esta es una configuración de registro para que podamos configurar esto yendo a la clave:
Base de datos Jet o versiones de Office anteriores a 2007
Para Windows de 32 bits:
HKEY_LOCAL_MACHINE\SOFTWARE\Microsoft\Jet\4.0\Engines\ODBC
HKEY_LOCAL_MACHINE\SOFTWARE\WOW6432Node\Microsoft\Jet\4.0\Engines\ODBC
Office 2007 a 2016 (instalaciones de MSI)
Para Office de 32 bits en Windows de 32 bits u Office de 64 bits en Windows de 64 bits:
HKEY_LOCAL_MACHINE\SOFTWARE\Microsoft\Office\X.Y\Access Connectivity Engine\Engines\ODBC
Para Office de 32 bits en Windows de 64 bits:
HKEY_LOCAL_MACHINE\SOFTWARE\WOW6432Node\Microsoft\Office\X.Y\Access Connectivity Engine\Engines\ODBC
(donde X.Y corresponde a la versión de Office que ha instalado)
Office 2016 u Office 365 (haga clic para ejecutar)
HKEY_LOCAL_MACHINE\SOFTWARE\Microsoft\Office\ClickToRun\REGISTRY\MACHINE\Software\Microsoft\Office\16.0\Access Connectivity Engine\Engines\ODBC
Debajo de la clave, ubique la clave TraceSQLMode y cambie el valor de 0 a 1. Access deberá reiniciarse si ya está abierto. De lo contrario, ábralo y ejecute algunas consultas. Se creará un archivo llamado sqlout.txt en la misma carpeta que el archivo de Access o en la carpeta de documentos.
Recomiendo usar Notepad ++ o un editor de texto similar que tenga la capacidad de detectar que se modificó. Luego le pedirá que vuelva a cargar el archivo. Eso le permite ver nuevas actualizaciones a medida que Access emite nuevos comandos para el archivo de texto sin una reapertura constante.
Ahora que tenemos habilitado el seguimiento de SQL, pasemos a los tipos de conjunto de registro.
Efecto de los tipos de Recordset en una consulta SELECT
Antes de comenzar, debemos comprender el efecto de los tipos de conjuntos de registros que elegimos para nuestras consultas. Es posible que haya notado que en una vista de diseño de formulario o en una vista de diseño de consulta, puede establecer el tipo de conjunto de registros. Por defecto, está configurado en Dynaset.
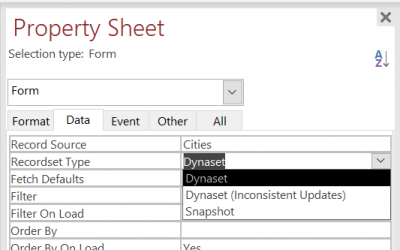
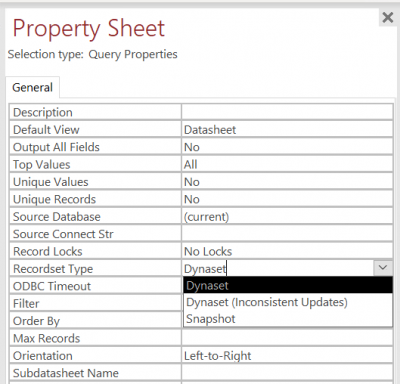
En VBA, tenemos pocas opciones más, pero no nos preocuparemos por ahora. Comencemos por entender qué significa exactamente Dynaset y Snapshot.
Recordsets de tipo Snapshot
Snapshot es bastante simple. Básicamente significa que tomamos un Snapshot del resultado en el momento de la ejecución de la consulta. Normalmente, esto también significa que Access no puede actualizar el resultado. Sin embargo, veamos cómo Access consulta la fuente con un conjunto de registros basado en Snapshot. Podemos crear una nueva consulta de Access de esta manera:
Como podemos ver en la vista, la consulta de SQL en Access es:
Access Query's SQLTransact-SQL SELECT Cities.* FROM Cities; 1 2 SELECT Cities.* FROM Cities;
Ejecutaremos la consulta y luego miraremos el archivo sqlout.txt. Aquí está la salida, formateada para facilitar la lectura:
SQLExecDirect: SELECT "CityID" ,"CityName" ,"StateProvinceID" ,"Location" ,"LatestRecordedPopulation" ,"LastEditedBy" ,"ValidFrom" ,"ValidTo" FROM "Application"."Cities" 1 2 3 4 5 6 7 8 9 10 11 SQLExecDirect: SELECT "CityID" ,"CityName" ,"StateProvinceID" ,"Location" ,"LatestRecordedPopulation" ,"LastEditedBy" ,"ValidFrom" ,"ValidTo" FROM "Application"."Cities"
Hubo pocas diferencias entre lo que escribimos en la consulta de Access en comparación con lo que Access envió a ODBC.
Analizando declaraciones ODBC
Tenga en cuenta las 3 diferencias:
1) Access calificó la tabla con el nombre del esquema. Obviamente, en el dialecto de Access SQL, eso no funciona de la misma manera, pero para el dialecto de ODBC SQL, es útil asegurarse de que estamos seleccionando de la tabla correcta. Eso se rige por la propiedad SourceTableName.
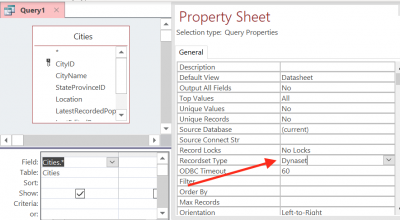
Ejecútelo nuevamente y veremos lo que obtenemos de sqlout.txt. Nuevamente, está formateado para facilitar la lectura:
SQLExecDirect: SELECT "Application"."Cities"."CityID" FROM "Application"."Cities" SQLPrepare: SELECT "CityID" ,"CityName" ,"StateProvinceID" ,"Location" ,"LatestRecordedPopulation" ,"LastEditedBy" ,"ValidFrom" ,"ValidTo" FROM "Application"."Cities" WHERE "CityID" = ? SQLExecute: (GOTO BOOKMARK) SQLPrepare: SELECT "CityID" ,"CityName" ,"StateProvinceID" ,"Location" ,"LatestRecordedPopulation" ,"LastEditedBy" ,"ValidFrom" ,"ValidTo" FROM "Application"."Cities" WHERE "CityID" = ? OR "CityID" = ? OR "CityID" = ? OR "CityID" = ? OR "CityID" = ? OR "CityID" = ? OR "CityID" = ? OR "CityID" = ? OR "CityID" = ? OR "CityID" = ? SQLExecute: (MULTI-ROW FETCH) SQLExecute: (MULTI-ROW FETCH)
¡Guau, están pasando muchas cosas! Esto es definitivamente más locuaz que un recordset de tipo snapshot. Repasemos uno por uno.
Análisis de declaraciones ODBC para un conjunto de registros dynaset
El primero solo selecciona la columna CityID. Esa es la clave principal de la tabla, pero lo más importante es que ese es el índice que Access está usando de su lado. Eso será importante cuando estudiemos las opiniones más adelante.
De eso podemos ver que es una búsqueda de una sola fila. Podemos usar las claves que obtuvimos de la primera consulta y recopilar el resto de columnas en esta consulta. Pero eso sería ineficiente si tuviéramos que hacer esto para todas las filas … Y ahí es donde entra la siguiente consulta. La tercera declaración es similar a la segunda pero tiene 10 predicados. Entonces, lo que esto significa es que cuando cargamos un formulario o una hoja de datos o incluso abrimos un conjunto de registros en código VBA, Access usará la versión de una sola fila o la versión de varias filas y completará los parámetros usando las claves que obtuvo del primero consulta.
Recuperación de fondo y resincronización
Por cierto, ¿alguna vez has notado cómo cuando abres un formulario o una hoja de datos, no puedes ver la X de Y en la barra de navegación?
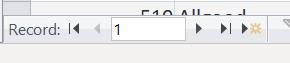
Esto se debe a que Access no puede saber cuántos hay hasta que haya terminado de recopilar los resultados de la primera consulta. Es por eso que a menudo puede encontrar que es muy rápido abrir una consulta que devuelve una gran cantidad de datos. Solo está obteniendo una vista previa de una pequeña ventana de todo el conjunto de registros mientras Access obtiene las filas en segundo plano. Si hace clic en el botón «Ir al último», es posible que congele el acceso. Tendría que esperar hasta que haya terminado de buscar todas las claves en la primera consulta antes de que podamos ver la «X de Y» en la barra de navegación.
Finalmente, debemos tener en cuenta que obtuvimos 3 tipos diferentes de ejecuciones, SQLExecDirect, SQLPrepare y SQLExecute. Puede ver que con el primero, no tenemos ningún parámetro. La consulta se ejecuta simplemente mientras que los que tienen parámetros se preparan y luego se ejecutan con SQLExecute. No podemos ver qué valores se pasaron realmente a esas declaraciones. Solo puede saber si obtuvo una sola fila o varias filas. Access usará la versión de varias filas para realizar la búsqueda en segundo plano y completar el conjunto de registros de forma incremental, pero usará la versión de una sola fila para llenar solo una fila. Ese podría ser el caso en una vista de formulario único en lugar de una vista de hoja de datos, formulario continuo o usarlo para resincronizar después de una actualización.
Navegando alrededor
Con un conjunto de registros lo suficientemente grande, es posible que Access no pueda terminar de recuperar todos los registros. Como se señaló anteriormente, el usuario recibe los datos lo antes posible. Normalmente, cuando el usuario navega hacia adelante a través del conjunto de registros, Access seguirá buscando cada vez más para mantener el búfer por delante del usuario.
¿Pero suponga que el usuario salta a la fila 100 usando el control de navegación e ingresando 100 allí? En ese caso, Access enviará las siguientes consultas …
SQLExecute: (MULTI-ROW FETCH) SQLExecute: (GOTO BOOKMARK) SQLExecute: (MULTI-ROW FETCH) SQLExecute: (MULTI-ROW FETCH)
Observe cómo Access usa las declaraciones ya preparadas que creó al momento de abrir el conjunto de registros. Como ya tiene las claves de la primera consulta, puede saber cuál es la fila «100». Lleva al usuario allí, luego comienza a llenar el búfer alrededor de esa fila número 100. Eso permite al usuario ver la fila número 100. El usuario también tiene una experiencia de navegación aparentemente rápida cuando hace clic en anterior o siguiente desde la nueva posición.
Pero incluso si el usuario dejara el formulario abierto, Access continuaría realizando tanto la búsqueda de fondo como la actualización del búfer para evitar mostrar los datos obsoletos del usuario. Eso se rige por la configuración de ODBC en el cuadro de diálogo Opciones, en la sección Avanzado de la pestaña Configuración del cliente:

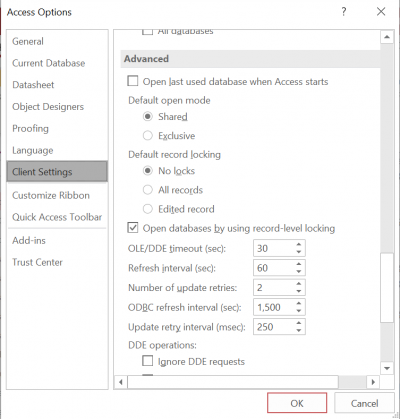
El valor predeterminado para el intervalo de actualización de ODBC es 1500 segundos, pero se puede cambiar. También se puede cambiar a través de VBA.
Resumiendo: Chunky o Chatty
La razón principal por la cual los conjuntos de registros de tipo dynaset son actualizables, pero los conjuntos de registros de tipo snapshot no lo son es porque Access puede sustituir una fila en el conjunto de registros con la versión más nueva del servidor, ya que sabe cómo seleccionar una sola fila. Esa información no estaba presente con un conjunto de registros de tipo de snapshot; acabamos de recibir una gran cantidad de datos. En la siguiente sección, revisaremos el efecto de modificar un conjunto de registros dynaset.
Analizamos 2 tipos principales de conjuntos de registros, aunque hay más. Sin embargo, el efecto no es tan significativo. En una sección posterior, consideraremos otros tipos de conjuntos de registros, incluido el Dynaset (Inconsistent).
Pero por ahora, es suficiente recordar que usar un snapshot es ser fornido en nuestra comunicación de red. Por otro lado, usar dynaset significa que seremos habladores. Ambos tienen sus altibajos.
Por un lado, el conjunto de registros de snapshot no necesita más comunicación con el servidor una vez que ha recuperado los datos. Mientras el conjunto de registros permanezca abierto, Access puede navegar libremente por su caché local. Access tampoco necesita mantener bloqueos y, por lo tanto, bloquear a otros usuarios. Sin embargo, un conjunto de registros de instantáneas es, por necesidad, más lento de abrir, ya que tiene que recopilar todos los datos por adelantado. Puede ser un ajuste deficiente para un gran conjunto de registros, incluso si tiene la intención de leer todos los datos.
Por ejemplo, si está creando un gran informe de Access de 100 páginas, generalmente vale la pena usar un conjunto de registros de tipo dynaset. Puede comenzar a representar la vista previa tan pronto como tenga suficiente para representar la primera página. Es mejor que obligarlo a esperar hasta que haya recuperado todos los datos antes de que pueda comenzar a procesar la vista previa. Aunque un conjunto de registros dynaset puede tomar bloqueos, generalmente es por un breve tiempo. Solo es lo suficientemente largo para que Access vuelva a sincronizar su caché local. Aún así, podría presentar problemas donde los usuarios se estancan. Veremos esto en una sección posterior.
Insertar un registro en un conjunto de registros
Hemos visto cómo el tipo de conjunto de registros afecta a SELECT. Sin embargo, un conjunto de registros no siempre es solo para navegar. Después de todo, cuando abrimos un conjunto de registros en VBA, un formulario de Access, ciertos tipos de consultas o incluso la propia tabla ODBC vinculada, podemos realizar modificaciones en los datos en cualquier caso. Independientemente de cómo abrimos el conjunto de registros, el comportamiento es principalmente similar. Comencemos con un insert.
Insertar un registro; una tabla con clave primaria no autoincrementable pero si autogenerada
Cuando insertamos un conjunto de registros (una vez más, cómo lo hacemos, a través de la interfaz de usuario de Access o VBA no importa), Access debe hacer cosas para agregar la nueva fila al caché local.
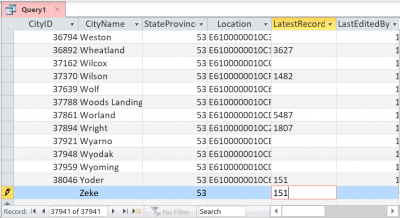
Lo importante a tener en cuenta es que Access tiene diferentes comportamientos de inserción dependiendo de cómo esté configurada la clave principal. En este caso, la tabla Ciudades no tiene un atributo IDENTITY sino que usa un objeto SEQUENCE para generar una nueva clave. Aquí está el SQL rastreado formateado:
SQLExecDirect: INSERT INTO "Application"."Cities" ( "CityName" ,"StateProvinceID" ,"LatestRecordedPopulation" ,"LastEditedBy" ) VALUES ( ? ,? ,? ,?) SQLPrepare: SELECT "CityID" ,"CityName" ,"StateProvinceID" ,"Location" ,"LatestRecordedPopulation" ,"LastEditedBy" ,"ValidFrom" ,"ValidTo" FROM "Application"."Cities" WHERE "CityID" IS NULL SQLExecute: (GOTO BOOKMARK) SQLExecDirect: SELECT "Application"."Cities"."CityID" FROM "Application"."Cities" WHERE "CityName" = ? AND "StateProvinceID" = ? AND "LatestRecordedPopulation" = ? AND "LastEditedBy" = ? SQLExecute: (GOTO BOOKMARK) SQLExecute: (MULTI-ROW FETCH)
Tenga en cuenta que Access solo enviará columnas que fueron modificadas por el usuario. Aunque la consulta en sí misma incluía más columnas, solo editamos 4 columnas, por lo que Access solo las incluirá. Eso garantiza que Access no interfiera con el comportamiento predeterminado establecido para las otras columnas que el usuario no modificó, ya que Access no tiene conocimiento específico sobre cómo la fuente de datos manejará esas columnas. Más allá de eso, la declaración de inserción es más o menos lo que esperaríamos.
La segunda declaración, sin embargo, es un poco extraña. Selecciona DONDE «CityID» ES NULO. Eso parece imposible, ya que sabemos que la columna CityID es una clave principal y, por definición, no puede ser nula. Sin embargo, si observa la captura de pantalla, nunca modificamos la columna CityID. Desde el punto de vista de Access, es NULL. Lo más probable es que Access adopte un enfoque pesimista y no supondrá que la fuente de datos se adherirá al estándar SQL. Puede que no sea una clave principal, sino simplemente un índice ÚNICO que puede permitir NULL. Para ese caso extremo poco probable, realiza una consulta solo para asegurarse de que la fuente de datos no haya creado un nuevo registro con ese valor. Una vez que ha examinado que no se devolvieron datos, intenta localizar el registro nuevamente con el siguiente filtro:
WHERE "CityName" = ? AND "StateProvinceID" = ? AND "LatestRecordedPopulation" = ? AND "LastEditedBy" = ?
que eran las mismas 4 columnas que el usuario realmente modificó. Dado que solo había una ciudad llamada «Zeke», obtuvimos solo un registro y, por lo tanto, Access puede llenar el caché local con el nuevo registro con los mismos datos que la fuente de datos tiene. Incorporará cualquier cambio a otras columnas, ya que la lista SELECT solo incluye la clave CityID, que luego usará en su declaración ya preparada para luego llenar toda la fila utilizando la clave CityID.
Insertar un registro; una tabla con clave primaria de autoincremento
Sin embargo, ¿qué pasa si la tabla tiene una columna de autoincremento como el atributo IDENTITY? El Access se comporta de manera diferente. Así que creemos una copia de la tabla Ciudades pero editemos para que la columna CityID sea ahora una columna IDENTITY.
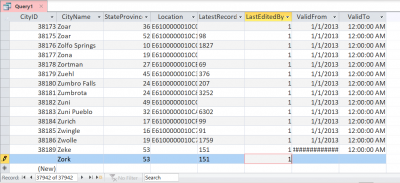
Tenga en cuenta el marcador de posición (Nuevo) que no estaba presente anteriormente.
Veamos cómo Access maneja esto:
SQLExecDirect: INSERT INTO "Application"."Cities" ( "CityName" ,"StateProvinceID" ,"LatestRecordedPopulation" ,"LastEditedBy" ,"ValidFrom" ,"ValidTo" ) VALUES ( ? ,? ,? ,? ,? ,?) SQLExecDirect: SELECT @@IDENTITY SQLExecute: (GOTO BOOKMARK) SQLExecute: (GOTO BOOKMARK)
Hay mucho menos charla; simplemente hacemos un SELECT @@IDENTITY para encontrar el identuty recién insertado. Lamentablemente, este no es un comportamiento general. Por ejemplo, MySQL admite la capacidad de hacer un SELECT @@IDENTITY, sin embargo, Access no proporcionará este comportamiento. El controlador ODBC de PostgreSQL tiene un modo para emular SQL Server para engañar a Access y que envíe la @@IDENTITY a PostgreSQL para que se pueda asignar al tipo de datos en serie equivalente.
Insertar un registro con un valor explícito para la clave primaria
Hagamos un tercer experimento usando una tabla con una columna int normal, sin un atributo IDENTITY. Aunque seguirá siendo una clave principal en la tabla, querremos ver cómo se comporta cuando insertemos la clave explícitamente.
SQLExecDirect: INSERT INTO "Application"."Cities3" ( "CityID" ,"CityName" ,"StateProvinceID" ,"LatestRecordedPopulation" ,"LastEditedBy" ,"ValidFrom" ,"ValidTo" ) VALUES ( ? ,? ,? ,? ,? ,? ,? ) SQLExecute: (GOTO BOOKMARK) SQLExecute: (MULTI-ROW FETCH)
Esta vez, no hay gimnasia extra; Como ya proporcionamos el valor de la clave primaria, Access sabe que no tiene que intentar encontrar la fila nuevamente; solo ejecuta la instrucción preparada para resincronizar la fila insertada.
Eso será relevante cuando veamos #Deleted problemas más adelante.
Actualización de un registro en un conjunto de registros
A diferencia de los inserts en la sección anterior, las actualizaciones son relativamente más fáciles porque ya tenemos la clave presente. Por lo tanto, Access generalmente se comporta de manera más directa cuando se trata de actualizar. Supongamos que modificamos solo una columna. Esto es lo que vemos en ODBC.
SQLExecute: (GOTO BOOKMARK) SQLExecDirect: UPDATE "Application"."Cities3" SET "CityName"=? WHERE "CityID" = ? AND "CityName" = ? AND "StateProvinceID" = ? AND "Location" IS NULL AND "LatestRecordedPopulation" = ? AND "LastEditedBy" = ? AND "ValidFrom" = ? AND "ValidTo" = ?
Hmm, ¿cuál es el trato con todas esas columnas adicionales que no modificamos? Bueno, de nuevo, Access tiene que adoptar una perspectiva pesimista. Tiene que suponer que alguien posiblemente podría haber cambiado los datos mientras el usuario revisaba lentamente las ediciones. Pero, ¿cómo podría saber Access que alguien más cambió los datos en el servidor? Bueno, lógicamente, si todas las columnas son exactamente iguales, entonces debería haber actualizado solo una fila, ¿verdad? Eso es lo que Access busca cuando compara todas las columnas; para asegurarse de que la actualización solo afectará exactamente una fila.
Pero … eso es un poco ineficiente, ¿no? Además, esto podría traer problemas si hay una lógica del lado del servidor que podría cambiar los valores ingresados por el usuario. Para ilustrar, supongamos que agregamos un trigger tonto que cambia el nombre de la ciudad:
CREATE TRIGGER SillyTrigger ON Application.Cities2 AFTER UPDATE AS BEGIN UPDATE Application.Cities2 SET CityName = 'zzzzz' WHERE EXISTS ( SELECT NULL FROM inserted AS i WHERE Cities2.CityID = i.CityID ); END;
Entonces, si intentamos actualizar una fila cambiando el nombre de la ciudad, parecerá que ha tenido éxito.
Pero si luego intentamos editarlo nuevamente, recibimos un mensaje de error con un mensaje actualizado:

Este es el resultado de sqlout.txt:
SQLExecDirect: UPDATE "Application"."Cities" SET "CityName"=? WHERE "CityID" = ? AND "CityName" = ? AND "StateProvinceID" = ? AND "Location" IS NULL AND "LatestRecordedPopulation" = ? AND "LastEditedBy" = ? AND "ValidFrom" = ? AND "ValidTo" = ? SQLExecute: (GOTO BOOKMARK) SQLExecute: (GOTO BOOKMARK) SQLExecute: (MULTI-ROW FETCH) SQLExecute: (MULTI-ROW FETCH)
Es importante tener en cuenta que el 2º GOTO BOOKMARK y MULTI-ROW FETCH no sucedieron hasta que recibimos el mensaje de error y lo descartamos. La razón es que a medida que ensuciamos un registro, Access realiza un GOTO BOOKMARK, se da cuenta de que los datos devueltos ya no coinciden con lo que tiene en la memoria caché, lo que hace que recibamos el mensaje «Los datos han cambiado». Tenga en cuenta que Access también descubrirá eventualmente el cambio si le damos suficiente tiempo para actualizar los datos. En ese caso, no habría mensaje de error; la hoja de datos simplemente se actualizará para mostrar los datos correctos.
Sin embargo, en esos casos, Access tenía la clave correcta, por lo que no tuvo problemas para descubrir los nuevos datos. ¿Pero si la clave es frágil? Si el disparador hubiera cambiado la clave principal o la fuente de datos ODBC no representara el valor exactamente como Access pensó que lo haría, eso provocaría que Access pintara el registro como “#Deleted”, ya que no puede saber si se perdió o si se perdió. eliminado legítimamente por otra persona.
De cualquier manera, obtener un mensaje de error o #Deleted” puede ser bastante molesto. Pero hay una manera de evitar que Access compare todas las columnas. Eliminemos el disparador y agreguemos una nueva columna:
ALTER TABLE Application.Cities2 ADD RV rowversion NOT NULL;
Agregamos una versión de fila que tiene la propiedad de estar expuesto a ODBC por tener SQLSpecialColumns (SQL_ROWVER), que es lo que Access necesita saber para poder usarlo como una versión de la fila. Veamos cómo funcionan las actualizaciones con este cambio.

Deja tu comentario